Scrapy 项目流程架构说明手册
Scrapy 的运行流程
Scrapy 的运行流程由以下几个步骤组成,每个步骤对应一个组件,分别负责请求的拦截、响应的解析、数据项的处理等任务:
- 中间件(Middleware):拦截和修改请求、响应的中间层。
- Spider:定义爬虫的主要逻辑,负责解析响应内容、生成数据项和新请求。
- 管道(Pipeline):对由 Spider 生成的数据项进行清洗和存储。
以下是对这些组件及其配置的说明,帮助快速理解 Scrapy 的架构及组件配置方法。
1. 中间件(Middleware)
中间件用于对请求和响应进行预处理和后处理。在 Scrapy 中,可以通过配置多个中间件,并按照优先级顺序执行。这使得我们可以通过中间件实现诸如设置代理、重试机制等功能。
示例代码:
1 | # middlewares.py |
中间件配置:
在 Scrapy 的 settings.py 文件中,可以通过 DOWNLOADER_MIDDLEWARES 来配置中间件,并指定其优先级(数值越小,优先级越高)。
1 |
|
注意:以上中间件代码和配置仅为演示,实际使用时需根据具体需求调整代理 URL 和重试逻辑。请注意优先级的配置值,确保中间件的执行顺序符合预期。
2. Spider
Spider 是 Scrapy 的核心组件之一,用于定义爬虫逻辑。每个 Spider 都包含 parse 等方法,用于解析页面数据、生成新的请求和数据项。
每个 Spider 的主要职责包括:
- 数据提取:从响应中提取数据。
- 生成新请求:在需要抓取其他页面时生成新请求。
- 生成数据项:将解析完成的数据封装为数据项,供管道处理。
示例代码:
1 | # spiders/example_spider.py |
Spider 配置:
可以在 settings.py 中通过 CONCURRENT_REQUESTS、DOWNLOAD_DELAY 等配置项控制 Spider 的抓取速度和请求频率,以防止被目标网站封禁。
1 | # settings.py |
注意:以上 Spider 和配置代码用于演示,具体配置需根据实际抓取任务调整,确保不会对目标站点造成负担。
3. 管道(Pipeline)
管道用于对 Spider 生成的数据项进行进一步处理,如数据清洗和存储。每个数据项会按顺序经过所有已定义的管道。
示例代码:
1 | # pipelines.py |
管道配置:
在 settings.py 中可以通过 ITEM_PIPELINES 配置管道的优先级(数值越小,优先级越高)。
1 | # settings.py |
注意:以上代码仅作结构示例,save_to_database 和 download_file 是假设的函数,需根据具体存储和下载需求实现。
4. Scrapy 的整体运行流程
在 Scrapy 的抓取流程中,各个组件通过以下步骤配合完成整个数据抓取任务:
- 请求处理 - 请求在发出前经过各个中间件处理,添加必要的信息。
- Spider 解析 - Spider 处理请求返回的响应,通过
parse等方法解析内容,生成数据项和新请求。 - 数据处理 - 解析生成的数据项被传递到管道,由管道完成清洗和存储。
- 任务完成 - Scrapy 引擎不断重复上述步骤,直到所有请求和数据项被处理完毕。
通过这种方式,Scrapy 实现了数据抓取的完整闭环,开发者可以通过配置不同的中间件、Spider 和管道,自定义每个流程环节的具体逻辑,满足各种数据抓取需求。
一个简单的Scrapy项目的流程图:
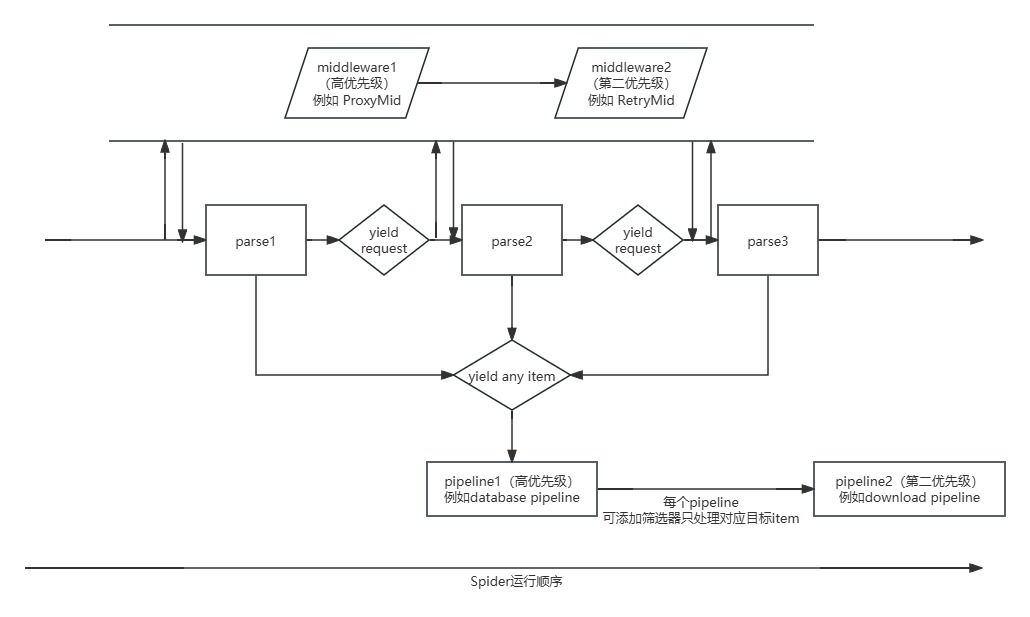
额外组件扩充
Scrapy 提供了一些额外的关键组件,帮助开发者更灵活、高效地构建爬虫。以下是对这些扩展组件及其配置的介绍。
1. 调度器(Scheduler)
调度器管理请求队列,确保所有请求被合理调度。其内部维护一个优先级队列,以保证高优先级的请求优先被处理。
配置示例:
在 settings.py 中设置调度器的请求队列持久化配置:
1 | # settings.py |
2. 下载器(Downloader)
下载器是 Scrapy 的核心组件之一,负责发送请求和接收响应。下载器结合中间件实现异步请求,从而提升爬取速度。
配置示例:
可以在 settings.py 中配置下载器的请求超时等参数:
1 | # settings.py |
3. 信号(Signals)
信号系统允许开发者在特定事件(如 Spider 开始和结束)触发时执行自定义代码,为爬虫添加钩子函数。
示例代码:
以下代码展示了如何使用信号系统在 Spider 开始时执行自定义逻辑。
1 | from scrapy import signals |
配置示例:
在 settings.py 中启用扩展,配置优先级以控制扩展的执行顺序:
1 | # settings.py |
4. 扩展(Extensions)
扩展功能允许在 Scrapy 中添加自定义模块,用于监控 Spider 运行状态或实现特殊逻辑。
配置示例:
可以在 settings.py 中启用和配置扩展的优先级:
1 | # settings.py |
通过配置以上组件,Scrapy 提供了强大的扩展性和灵活性。开发者可以根据爬虫任务需求,对每个组件及其配置进行精细控制,从而实现高效、可扩展的爬虫项目。




